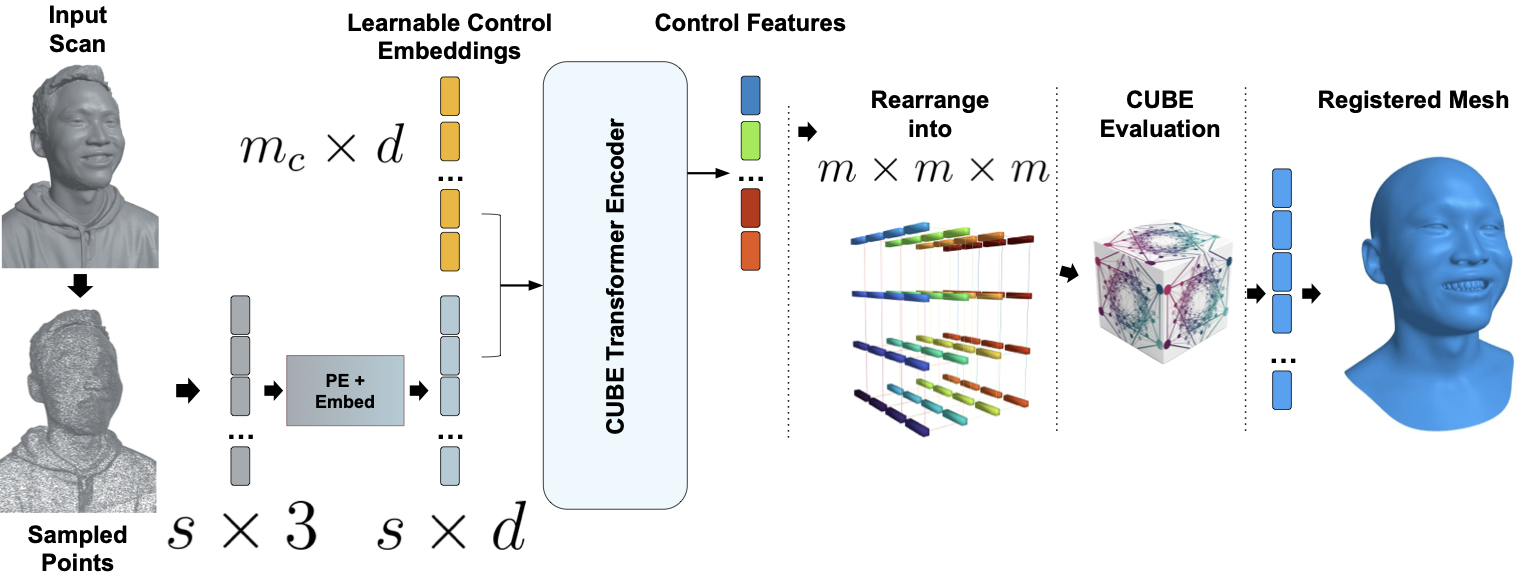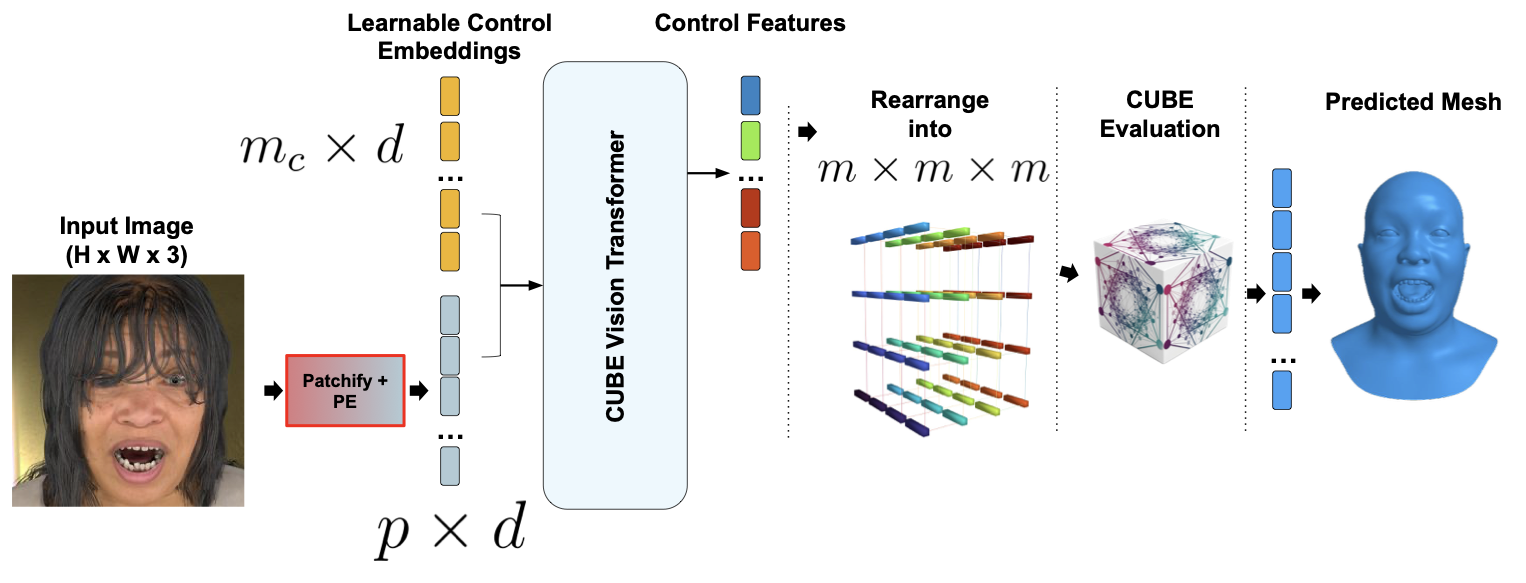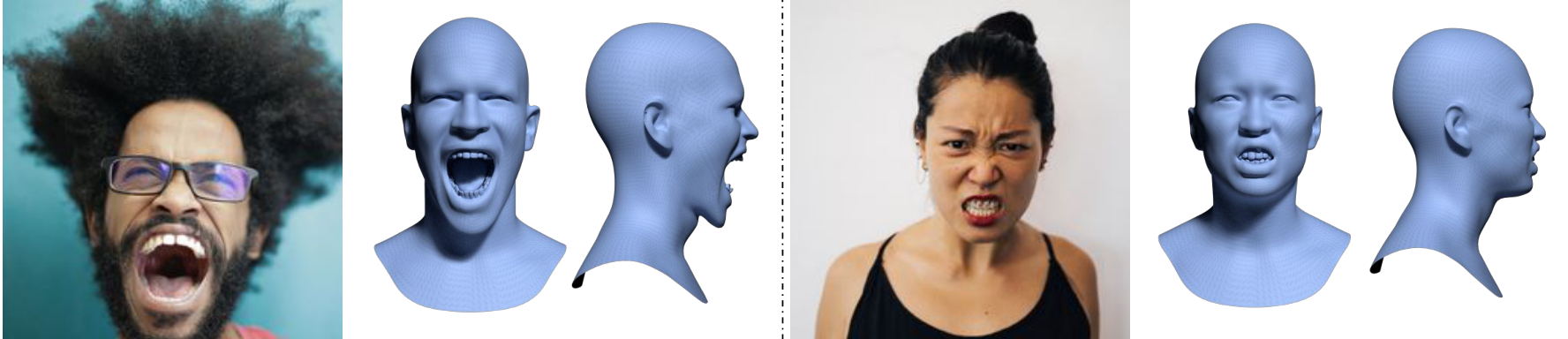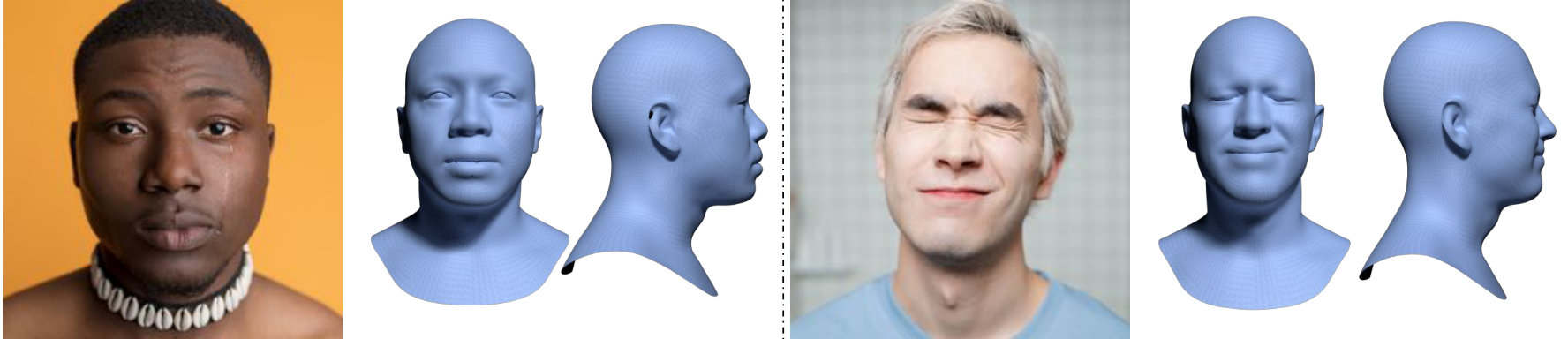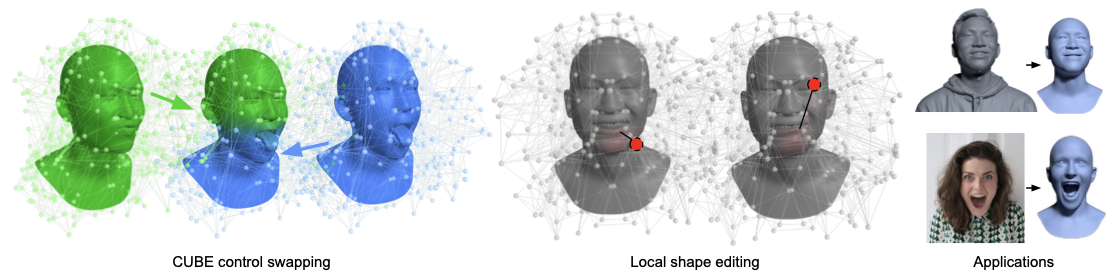
The CUBE representation
Defined by a lattice of high-dimensional control features, CUBE reconstructs a 3D face in a two-stage process. First, 3D coordinates are sampled from a fixed template mesh. These coordinates are then mapped to high-dimensional features via B-spline interpolation using the lattice of control features. The first three values of the resulting high-dimensional feature vector form a coarse base shape. Finally, the full feature vector is input to a small MLP, which predicts coordinate offsets (residuals) from the base shape, resulting in the refined 3D point coordinates.